Rows: 1,629
Columns: 8
$ qsmk <fct> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 1, 0, 0, …
$ death <fct> 0, 0, 0, 1, 0, 0, 0, 0, 1, 1, 0, 1, 0, 0, 1, 0, 0, 0, 1, 0, …
$ time <dbl> 120, 120, 120, 26, 120, 120, 120, 120, 22, 46, 120, 119, 120…
$ smokeyrs <dbl> 29, 24, 26, 53, 19, 21, 39, 9, 37, 25, 24, 20, 19, 38, 41, 2…
$ sex <dbl> 0, 0, 1, 0, 0, 1, 1, 1, 0, 0, 0, 0, 1, 1, 1, 1, 0, 1, 0, 1, …
$ age <dbl> 42, 36, 56, 68, 40, 43, 56, 29, 51, 43, 43, 34, 54, 51, 71, …
$ race <dbl> 1, 0, 1, 1, 0, 1, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, …
$ education <dbl> 1, 2, 2, 1, 2, 2, 3, 3, 2, 2, 3, 3, 1, 3, 1, 3, 3, 3, 3, 2, …1 绪论
1.1 研究背景与问题提出
- 吸烟对健康及寿命影响的研究现状
- 生存分析方法在健康研究中的应用与发展
- Restricted Mean Survival Time (RMST) 与 Causal Survival Forests 方法的理论价值
## 本研究的创新点
1.2 2. 文献综述
- 吸烟对寿命影响的流行病学研究回顾
- 生存分析在因果推断中的应用与挑战
- RMST 方法在异质性处理效应估计中的应用
- Generalized Random Forests (GRF) 包及 Causal Survival Forests 方法的原理与实践
- 现有 R 包的功能局限及本研究 R 包 inga 的创新点
1.3 3. 理论基础与方法论
- 生存分析基础理论
- 生存函数、累积分布函数与风险函数
- 右删失(Right-Censoring)数据的处理原理
- 生存函数、累积分布函数与风险函数
- 限制性平均生存时间(RMST)方法论
- RMST 的定义、计算原理与统计推断方法
- RMST 在异质性处理效应(HTE)估计中的优势
- RMST 的定义、计算原理与统计推断方法
- Causal Survival Forests 方法的原理与算法框架
- 因果推断的理论基础
- 基于 GRF 的 Causal Survival Forests 算法
- 异质性处理效应估计的策略
- 因果推断的理论基础
- 研究假设、模型设定与统计推断框架
1.4 4. 数据来源与研究设计
- 数据来源及数据特征描述
- 吸烟数据的变量说明及编码策略
- 数据预处理与清洗方法
- 缺失值处理
- 数据标准化与转换
- 缺失值处理
- 因果推断研究设计
- RMST 模型的参数设置与实现
- Causal Survival Forests 模型的参数调优与性能评估
- RMST 模型的参数设置与实现
1.5 5. 结果分析
- 数据的描述性统计分析
- 吸烟对寿命影响的估计结果
- RMST 方法的结果呈现与解释
- Causal Survival Forests 方法的结果呈现与解释
- RMST 与 Causal Survival Forests 的结果比较
- 结果的图表可视化与深入分析
1.6 6. R 包 inga 的开发与实现
- inga 包的设计目标与功能定位
- 包的结构设计与模块划分
- 核心函数的算法原理与实现细节
- 数据导入、RMST 计算与可视化功能的开发
- 函数性能测试与结果验证
- 用户指南与代码示例
1.7 7. 吸烟数据的完整分析复现及扩展应用
- 使用 inga 包复现吸烟数据分析的完整流程
- 在其他生存数据集上的扩展应用分析
- 数据结果的可视化与解释
1.8 8. 讨论
- 研究结果的理论意义与现实意义
- RMST 方法与 Causal Survival Forests 方法的比较分析
- 吸烟对寿命影响的异质性分析
- 数据局限性与方法学缺陷探讨
- 对未来研究的展望
1.9 9. 结论
- 研究发现的总结
- 本研究的理论贡献与实践价值
- R 包 inga 的应用潜力与推广前景
- 对进一步研究的建议
1.10 10. 参考文献
1.11 11. 附录
- 数据集变量说明表
- 论文中使用的数学符号说明表
- R 包 inga 的详细用户手册
- 关键代码实现片段
文中出现的NHEFS数据集,及一些缩写与数学符号解释:
| 变量名 | 解释 |
|---|---|
| death | 是否在1992.12前死亡(1:是,0:否) |
| time | 存活时间,NA:Administrative censoring |
| qsmk | 处理变量,是否停止吸烟(1:是,0:否) |
| age | 年龄 |
| smokeyrs | 烟龄 |
| 缩写 | 全称 |
|---|---|
| ACE | average causal effect(平均因果作用) |
| DAG | directed acyclic graph(有向无环图) |
| ACE | average causal effect(平均因果作用) |
| RMST | restricted mean survival time |
| IPW | Inverse Propensity Score |
| 符号 | 解释 |
|---|---|
| \(pr(\cdot)\) | 概率 |
| \(\perp\!\!\!\!\perp\) | 独立 |
| \(Y_i(1), Y_i(0)\) | potential outcomes of unit \(i\) under treatment and control |
| \(\tau\) | ACE,\(E\{Y(1)-Y(0)\}\) |
| \(\mu_1(X)\) | \(\mu_0(X) = E(Y\mid Z=1, X)\) |
| \(\mu_0(X)\) | \(\mu_0(X) = E(Y\mid Z=0, X)\) |
| \(e(X)\) | \(e(X) = pr(Z=1\mid X)\) |
| \(\tau_c\) | \(\tau_c = E{ Y(1) - Y(0)\mid U=C}\) |
| \(U\) | 未考虑的混杂因子 或者 个体类型 |
| \(Z\) | treatment(处理) |
| \(X\) | pretreatment covariate |
| \(D_k\) | 事件的时间变化指标,\(if\ T<k,D_k=1,else\ D_k=0\) |
| \(C_k\) | 删失的时间变化指标,\(if\ k_{end}<k,C_k=1,else\ C_k=0\) |
2 研究背景
2.1 什么是因果推断?————from casual to causal
2.1.1 从相关性与辛普森悖论2说起
统计学中有句著名的话:correlation does not imply causation(相关不代表因果).Fisher曾就吸烟与死亡的强相关性提出了那个著名的问题:吸烟会导致死亡吗?他以为或许人体中有某种unmeasured gene,导致了人吸烟和肺癌等疾病,吸烟与死亡的强相关性是这个基因导致的当我们控制这个基因相同时,强相关性便消失了.
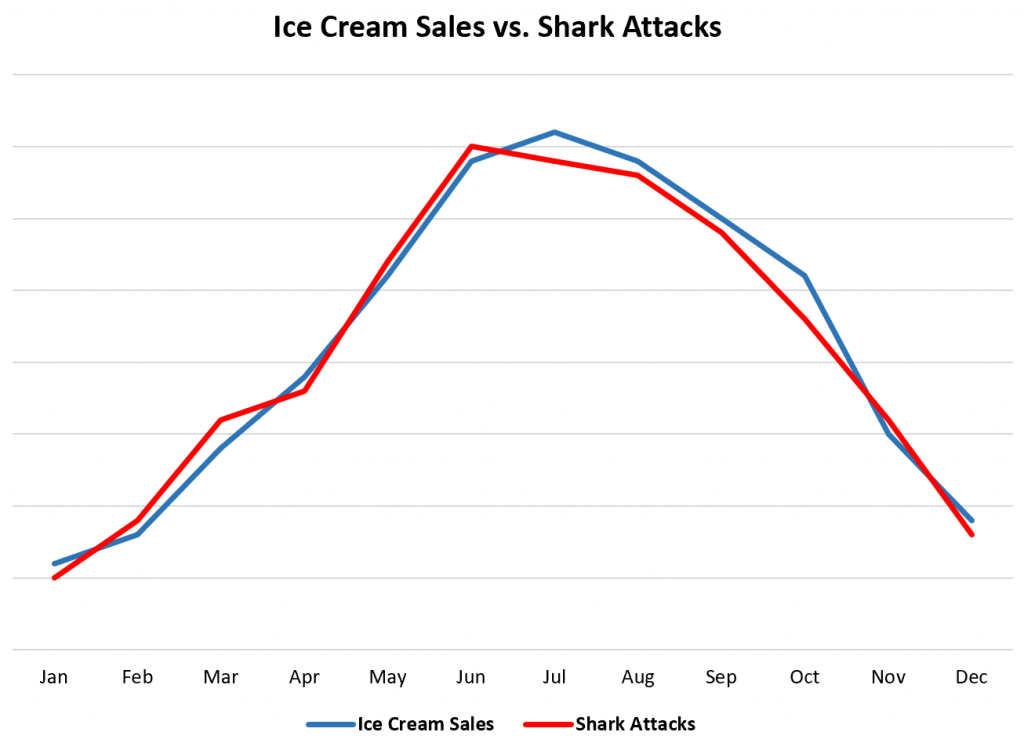
相关性往往在一些casual的观察性研究中被直接视为因果性,或被视为拥有因果性的证据,吸烟与肺癌的强相关性等同于吸烟导致肺癌?这在人类直觉上是正确的,但还有着一些直觉上就没有关系的事件存在强相关性.图 1 清晰展示了相关性的不可靠,并不是售卖冰淇凌导致鲨鱼袭击,或者鲨鱼袭击导致冰淇凌畅销,而是气温导致了两者的强相关!
在分辨相关与因果的问题上, (A. B. Hill 1965)提出了著名的九条准则:
- Strength of Association:强关联更可能表明因果关系。
- Consistency:在不同的研究和人群中,一致观察到关联。
- Specificity:关联特定于特定的疾病和暴露。
- Temporality:暴露在疾病发生之前。
- Biological Gradient:存在剂量-反应关系;暴露越大,患病风险越高。
- Plausibility:根据现有知识,关联在生物学上是合理的。
- Coherence:关联与已知的疾病自然史和生物学事实不冲突。
- Experiment:实验证据支持关联。
- Analogy:在类似的因素中观察到类似的关联。
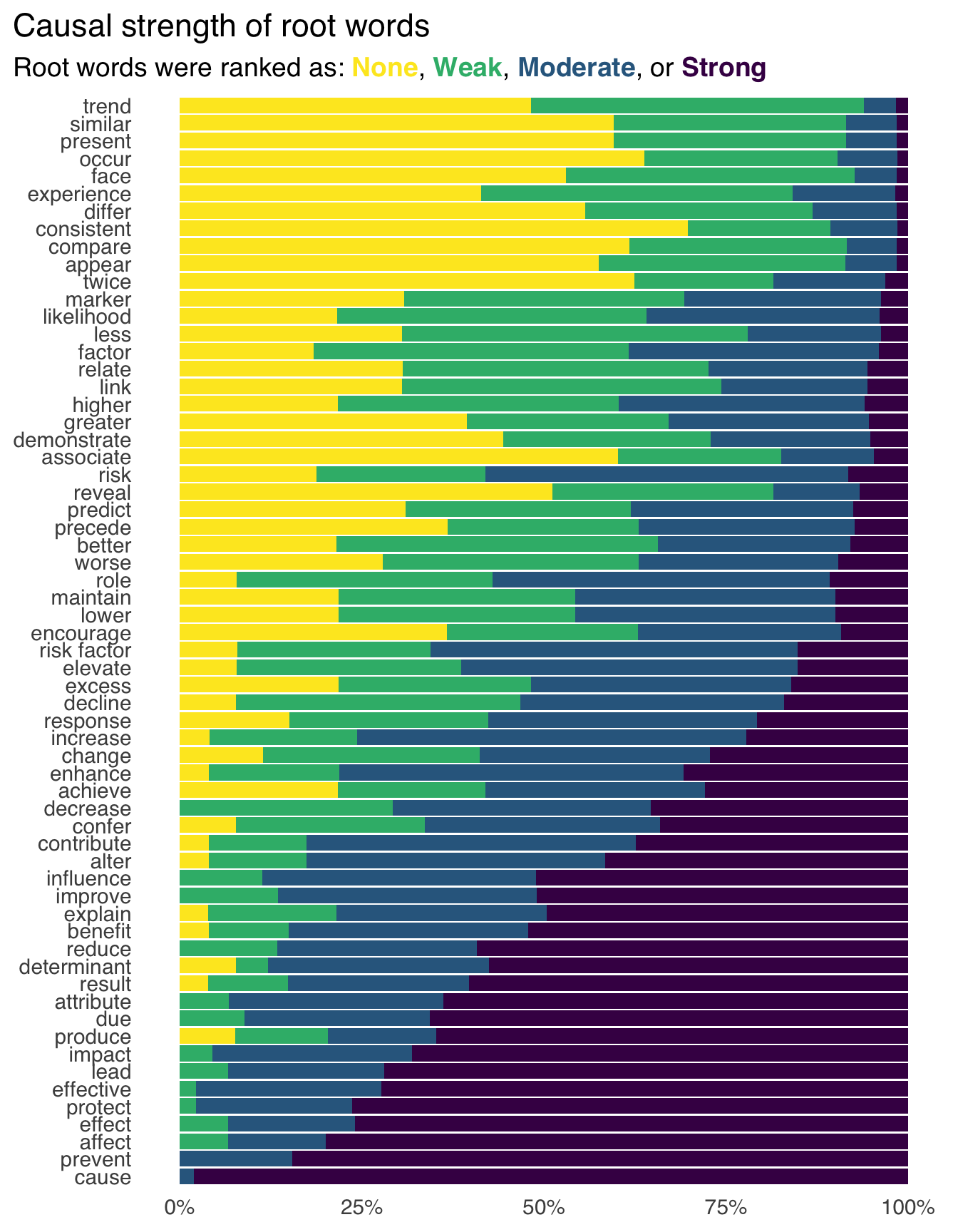
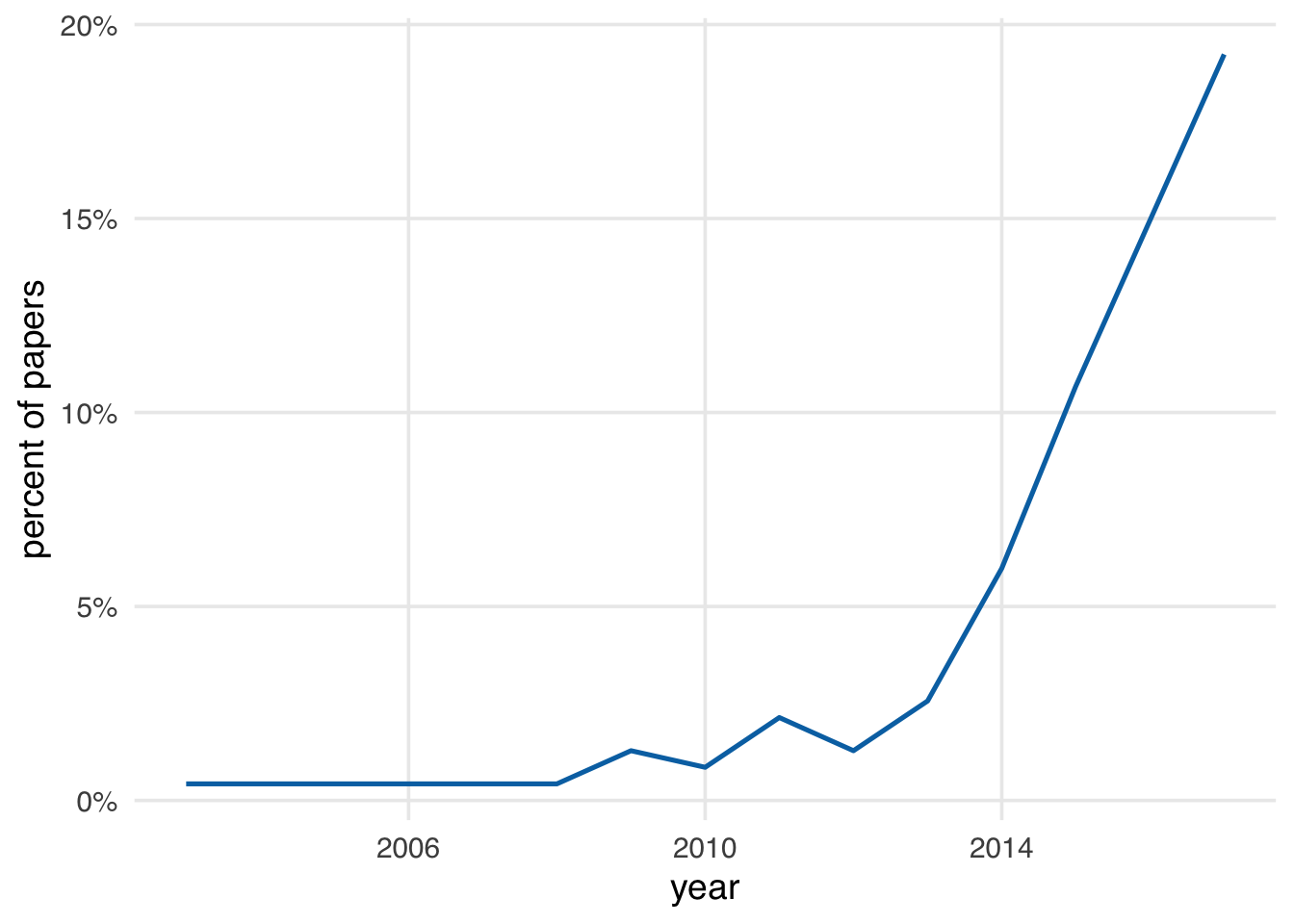
实际上,随着因果推断的显学化,在观察性卫生研究领域,近年来大部分研究人员都已经注意到了”association”并不等同于因果关系,并谨慎代表因果性的词语,但他们会认为相关性暗示了因果性,并随之给出建议,且其中只有4%的研究论文使用了因果推断的模型来评估因果作用[图 2](S. A. B. Hill 2022).
由 表 1 所示
2.2 因果推断基础(基于潜在结果框架)
2.2.1 基础概念
2.2.1.1 potential outcome
恰如Robert Frost的一首诗歌:
黄色的树林里分出两条路,
可惜我不能同时去涉足。
2.2.1.2 基础假设
以下是一些因果推断语言常用到的假设:
定义 1 (SUTVA)
无干涉(no interference)实验个体间互不干涉,用数学语言表述就是 \(\forall i \neq j, \{Y_i(1),Y_i(0) \}\perp\!\!\!\!\perp Z_j\)
一致性(consistency):treatment没有其他版本,即其被良好定义了,无歧义.
以吸烟问题为例,就是实验个体间互不干涉,一个人的吸烟与否不会影响到另外一个人的潜在结果.一个人的处理只有两种,继续吸烟或者停止吸烟,不会突然再冒出另外一个吸大麻的处理.
定义 2 (Igonrablity) 可忽略性假设(Ignorability)。给定协变量 \(X\),干预的分配 \(Z\) 独立于潜在结果,即 \(Z \perp \!\!\! \perp Y(0), Y(1)|X\)。这个假设也有其他名字,unconfoundedness 或者 exchangability
还是以吸烟问题为例
定义 3 (overlap) 即要假设当控制协变量X的水平时,处理有取得1或0的可能,而不是只能1或0.
overlap假设(or positivity)表示为公式即:
\[ e(X)=P(Z=1 |X=x)>0, \quad \forall z \text { and } x \]
如果对于某些 \(X\) 的值,干预分配是确定的,则对于这些值来说,至少有一项干预所导致的结果是无法被观测的,这样我们也就无法去估计处理的因果效应。在吸烟中,假定有两种处理:1 and 0,如果说年龄大于 30 岁的总是继续吸烟,则我们就无法(也没有意义)去研究不吸烟在这些患者上的干预效果(with ipw)。甚至于说e(X)即便不等于0,太小或太大了也不行,这样估计的ACE会具有极大的方差,很不可靠.
2.2.2 因果图(causal diagram)
为了将因果问题可视化, (Pearl 1995) 提出了用DAG作为因果图来描述事件间的因果关系.在CRT中,结果可能的成因有非常多,但实验中对结果有因果效应的只有随机化本身.但在非随机实验中,因果结构可能会非常复杂.因果图有助于传达我们对这个结构的看法。除了对我们认为的因果结构是什么持开放态度之外,因果图还具有令人难以置信的数学特性,使我们能够找到一种方法来估计无偏的因果效应,即使是用观察数据。换句话说,如果正确指定,它们可以帮助我们实现可交换性。
近年来已有越来越大比例的医学领域论文中使用了因果图,如 图 4 所示.
2.2.2.1 混杂因子
2.3 Causal survival analysis(Hernan 和 Robins 2025)
在前面的讨论中,我们一直关注一些在特定时间点发生的,估计对结果的处理效应的因果问题。然而,也有许多因果问题关心处理对事件发生时间的因果效应。例如,我们可能想要估计戒烟对死亡时间的因果影响(无论个体何时死亡)。这属于生存分析领域。
在生存分析中,或者在“事件发生时间分析”中,我们关心的是事件发生的时间,那么我们该怎么估计处理对事件发生时间的平均因果作用呢?如果在该理想实验中没有任何删失,也没有任何confounder,那么我们可以很方便地使用\(\tau = E(T\mid A=1)-E(T\mid A=0)\)来估计ACE.
然而,实验数据中一般存在大量Administrative censoring:由于经费或其他原因,研究者会设定实验的结束日期,在实验的结束日期后的信息我们一无所知,除了我们知道T将大于实验的持续时间,其实也就是右删失.除了Administrative censoring外,如其他因果分析一样,生存分析也存在non-administrative censoring,例如跟踪丢失(例如退出实验)和竞争事件(见 定义 4 )。
定义 4 (竞争事件(Competing events)) 竞争事件是指阻止感兴趣事件(例如中风)发生的事件(通常为死亡):因其他原因(比如癌症)死亡的个体永远无法患上中风。在生存分析中,关键在于是否将竞争事件视为一种非行政性删失。
- 若将竞争事件视作删失事件,那么该分析实则是在尝试模拟这样一个群体:其中因其他原因所致的死亡在某种程度上要么被消除,要么与中风的风险因素相互独立。由此产生的因果效应估计值难以解读,且可能与有意义的估计量并不相符。此外,在零假设下,这种删失可能会引入选择偏差,这就需要利用所关注事件的测量风险因素数据进行调整(比如通过逆概率加权)。
- 如果竞争事件不被认为是删失事件,那么分析有效地将事件的时间设置为无限。也就是说,死亡的个体被认为在他们死亡和随访行政结束之间发生中风的概率为零。治疗对中风影响的估计很难解释,因为治疗对死亡的直接影响可能产生非零估计,这将防止中风的发生。
那么,当遇到这些删失时,我们该如何估计\(\tau\)呢, (Hernan 和 Robins 2025) 中说明了以下方法:
2.3.1 administrative censoring
2.3.1.1 简单的情形
现在让我们回到刚开始便提到的经典因果问题吧,吸烟会导致死亡率上升吗,是不是有其他变量导致了他们两者间的关联呢,例如人体内有种未知的基因同时导致二者?我们该如何估计停止抽烟A(1:yes,0:no)对死亡时间T的平均因果作用(T开始于跟踪实验的日期)呢?NHEFS为此开展了一次长达十几年的研究,表 2中含有该数据集的基本情况.
| name | desc | stats | id |
|---|---|---|---|
| qsmk | 0 | 1201 (73.7%) | qsmk0 |
| 1 | 428 (26.3%) | qsmk1 | |
| death | 0 | 1311 (80.5%) | death0 |
| 1 | 318 (19.5%) | death1 | |
| time | Mean ± SD | 108.5 ± 27.3 | time |
| smokeyrs | Mean ± SD | 24.9 ± 12.2 | smokeyrs |
| sex | Mean ± SD | 0.5 ± 0.5 | sex |
| age | Mean ± SD | 43.9 ± 12.2 | age |
| race | Mean ± SD | 0.1 ± 0.3 | race |
| education | Mean ± SD | 2.7 ± 1.2 | education |
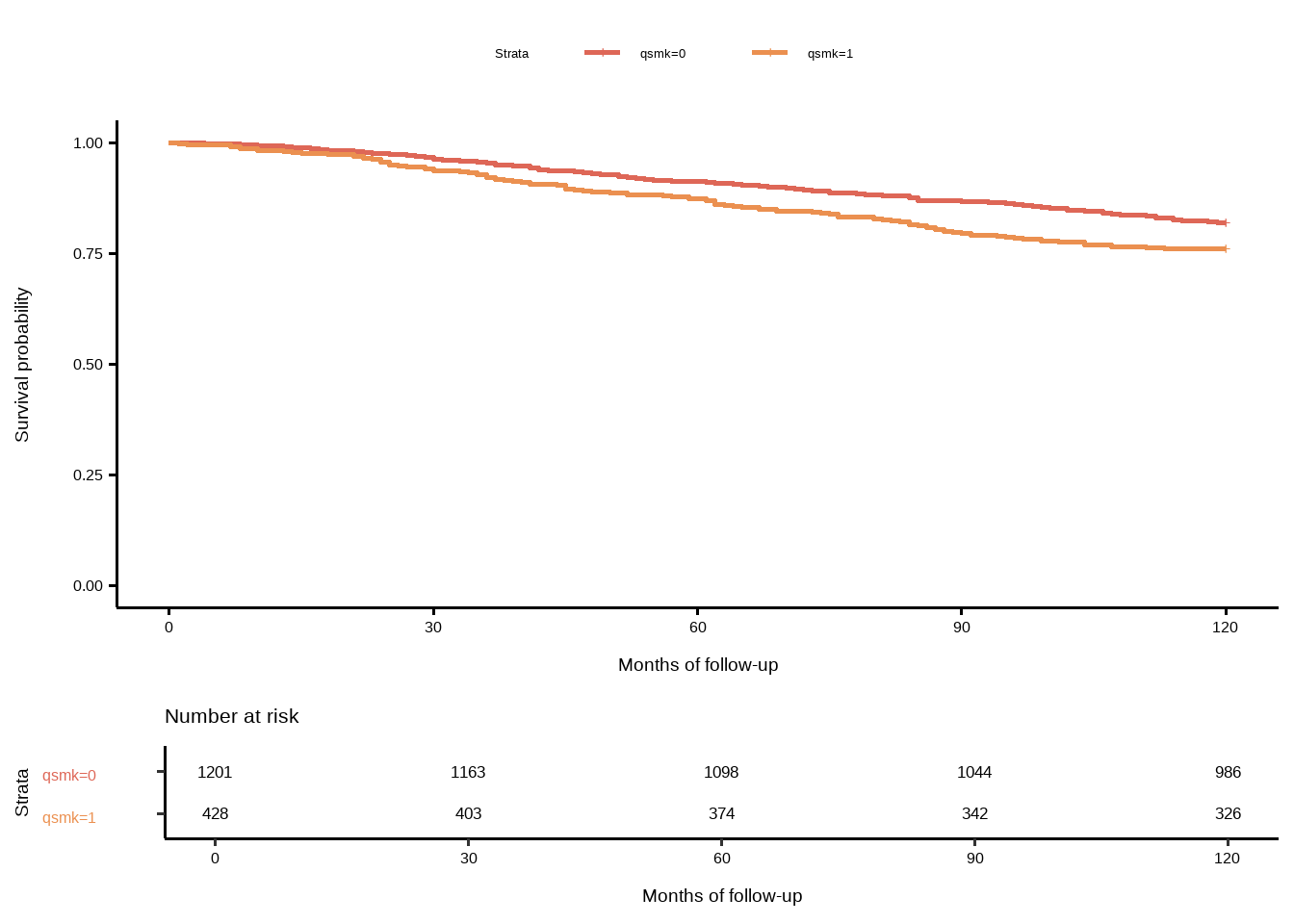
在这个数据集中,死亡时间T可从1个月取值到120个月,删失仅仅发生在实验结束的时间点\(k_{end}\),但其中只有318个未删失个体,其余个体均存活超过了120个月,处理是实验开始时便定好的,非随时间改变的变量,因此我们不能简单地使用\(E(Y\mid Z=1)-E(Y\mid Z=0)\)来估计ACE(更何况Z也不是随机分配的),一般的做法是使用the survival probability, the risk, and the hazard ritio来measure ACE,如 KM生存曲线图 6 所示,直接对比两组的生存曲线,\(Pr [T > k\mid Z = 1]\)比$Pr [T > kZ = 0] $ 更低,但是我们并不能由此得出因果解释,因为
\[ Z \not \perp \!\!\! \perp\ T(1), T(0) \]
当然我们也可以使用风险比: \[ \frac{Pr\{T=k\mid T>k-1,Z=1\}}{Pr\{T=k\mid T>k-1,Z=0\}} \]
来measure ACE,但这种做法有很多问题.首先,风险比往往是随时间变化的,很多生存分析却只拟合了一个Cox proportional hazards model获得一个风险比(可以理解为将各个时间点的风险比添加权重平均而得),忽略了\(Z\times T\)这个交互项,这使得该风险比是难以解释的:即使生存曲线不同,风险比仍有可能为1.其次,即使我们计算了特定时间的风险比,比如说T=k+1时的风险比,无妨假设处理是有害的,处理组在T=k时所有高风险个体已经死亡了,留下的都是低风险个体,而控制组仍保留着两种个体(因为处理并没有将高风险个体清除),那么在\(HR_{k+1}\)将会小于1,这显然与我们想要预估的真实因果作用相反.
为了将信息表述的更加清晰,我们引入\(D_k\),在中的因果图展示了Z,U与D1,D2间的关系,接下来我们便可定义 \(S(T=k)=Pr(D_k=0)\) , \(R(T=k)=Pr(D_k=0)\)和\(h(T=k)=Pr(D_k=1\mid D_{k-1}=0)\),此外还有
\[ \begin{aligned}\Pr\left[D_k=0\right]=\prod_{m=1}^k\Pr\left[D_m=0|D_{m-1}=0\right]\end{aligned} \tag{1}\]
有两种简单的方法来估计\(Pr(D_k=1\mid D_{k-1}=0)\),非参数估计为将在k发生的事件除以所有仍存活的个体,参数估计为拟合 logistic 模型:
\[ \mathrm{logit~Pr}\left[D_{k+1}=1|D_k=0,Z\right]=\theta_{0,k}+\theta_1Z+\theta_2Z\times k+\theta_3A\times Z^2 \]
接下来我们根据式 1将个时间点的风险估计值相乘得到存活率的估计值即可,通过这种做法我们可以得到更加平滑的生存曲线,但要求我们对风险的假设模型是合理的,“所有模型都是错的,但有些是有用的”.
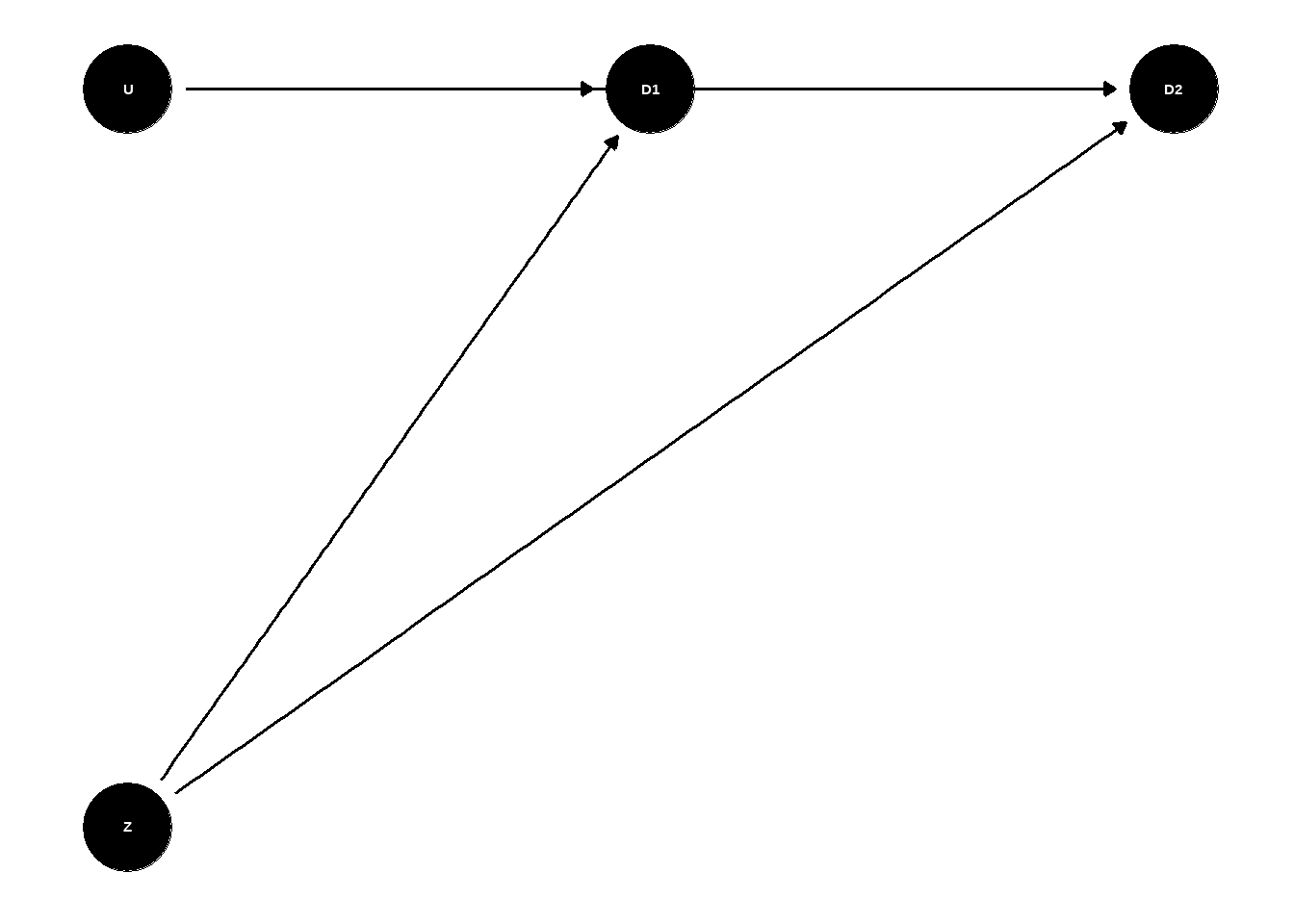
2.3.1.2 更随机的删失
上面的例子中参与者都是同步进入实验的,现在假设他们是异步加入实验的,此时不同个体间的删失时间将会不同了,尽管他们退出实验的日期是相同的,此时该如何去估计本该被观察到的生存曲线呢(假如所有人都未被删失),即要估计\(Pr(D_k=0\mid Z=z)\),简单计算在组z内,在时间点k存活且未删失的时间肯定是不行的,其是\(Pr(C_{k+1}=0,D_{k+1}=0 \mid Z=z)\)的估计量.
假设删失是随机分配的\(Pr(D_k=0\mid Z=z)\)可以用式 2来识别
\[ \begin{aligned}\prod_{m=1}^k\Pr\left[D_m=0|D_{m-1}=0,C_m=0,Z=z\right]\mathrm{~for~}k<k_{end}\end{aligned} \tag{2}\]
2.3.1.3 混淆因子(IPW)
当 \[Z \not\perp \!\!\! \perp\ T(1), T(0)\] 时,我们显然不能直接对比生存曲线来获得因果解释,图 6中抽烟组的生存率更高,这并不能说明抽烟会提高生存率,而是可能由老人倾向于停止抽烟导致,
假设\(Z \!\perp\!\!\!\perp T(1),T(0)\mid X\)和\(0<e(X)<1\),简单的代数计算便可得到\(Z \!\perp\!\!\!\perp T(1),T(0)\mid e(X)\),我们有:
\[ \tau=E\{T(1)-T(0)\}=E\left\{\frac{ZT}{e(X)}-\frac{(1-Z)T}{1-e(X)}\right\}. \]
3 文献综述
3.1 评估混杂因子的一种方法:Restricted Mean Time Lost(RMTL)
3.1.1 背景与动机
在临床和流行病学研究中,常常要对生存数据的进行分析来评估药物对于结果的作用,“Competing Risks” 即竞争风险(当一个个体可能经历多个潜在事件(如多个可能的疾病或死亡原因)时,这些事件被称为“竞争风险”),在因果推断中被称为”confounder”,通常依赖于风险比(Hazard Ratio, HR)来评估,而本篇论文提出了一种新的评估方法:Restricted Mean Time Lost(RMTL)(Wu 等 2023)。
对于竞争风险数据(即感兴趣的事件可能因其他竞争事件被阻止发生),通常采用两种方法:
- 原因特异性风险比(cHR):基于特定事件发生的瞬时率。
- 子分布风险比(sHR):基于累积发生率函数。
- 这些方法的局限性:
- cHR和sHR的临床解释不直观,尤其在缺乏基线风险\(h_0(t)\)的情况下难以理解。
- 依赖比例风险假设,在假设被违反时,单一HR难以准确反映实际情况。
- 仅描述相对变化,忽略了绝对影响。
此时,基于受限均时间损失(Restricted Mean Time Lost, RMTL)的一种基于时间尺度的绝对测量方法,以改善上述不足。
3.1.2 2. 方法
3.1.2.1 2.1 RMTL的定义
- RMTL 是在特定时间窗口内,由某种原因导致的平均时间损失。它等价于累积发生率函数(CIF)曲线下的面积: \[ RMTL = \int_0^{\tau} CIF(t) dt \] 其中,\(\tau\) 是选定的时间点。
- RMTL的差异(RMTLd) 量化了两组之间的绝对时间损失差异: \[ RMTLd = RMTL_{\text{组1}} - RMTL_{\text{组2}} \]
3.1.2.2 2.2 假设检验
- 提出基于RMTLd的检验:
- 原假设((H_0)):两组之间的RMTLd = 0(无差异)。
- 备选假设((H_1)):两组之间的RMTLd ≠ 0。
- 检验统计量 (Z_d) 服从标准正态分布: \[ Z_d = \frac{\hat{\Delta}}{\sqrt{\text{Var}(\hat{\Delta})}} \]
- 置信区间为: \[ \hat{\Delta} \pm z_{\alpha/2} \cdot \sqrt{\text{Var}(\hat{\Delta})} \]
3.1.2.3 2.3 样本量计算
- 提出了基于RMTLd的样本量公式,适用于不同组间比例和给定统计能力。
3.1.3 3. 模拟研究
3.1.3.1 3.1 研究设计
- 模拟了6种竞争风险场景,评估RMTLd测试的性能:
- 无组间差异:两组之间的事件发生率曲线相同。
- 比例风险假设成立:组间差异恒定(小或大)。
- 非比例风险场景:组间差异出现在早期或晚期。
3.1.3.2 3.2 主要结果
- 估计精度:RMTLd的估计偏差小,覆盖率合理,随样本量增加而提高。
-
假设检验性能:
- 在比例风险假设成立时,RMTLd测试的统计能力与传统Gray测试相当。
- 在非比例风险场景中,RMTLd测试的能力显著优于Gray测试。
-
样本量计算:
- RMTLd测试的样本量计算准确性较高,能够保证预设的80%统计能力。
3.1.4 4. 实例分析
3.1.4.1 实例1:宫颈癌数据
- 数据来源:美国癌症监测项目(SEER)。
- 问题:分析手术对宫颈癌死亡的影响。
- 结果:
- RMTL:无手术组平均损失7.485年,手术组为1.346年。
- RMTLd:两组之间的差异为-6.139年,表明无手术患者因癌症平均多损失6.139年寿命。
- 优势:相比cHR和sHR,RMTLd的时间尺度解释更直观。
3.1.4.2 实例2:急性淋巴细胞白血病
- 数据来源:欧洲血液和骨髓移植组。
- 问题:评估供体-受体性别匹配对生存的影响。
- 结果:
- RMTLd为-1.023年,显示性别不匹配患者平均损失更多的生存时间。
- cHR和sHR未能准确反映组间差异,因为比例风险假设被违反。
3.1.4.3 实例3:COVID-19治疗试验
- 数据来源:重建自COVID-19治疗试验(ACTT-1)。
- 问题:评估瑞德西韦对恢复时间的影响。
- 结果:
- RMTL:瑞德西韦组的恢复天数为13.286天,安慰剂组为10.859天。
- RMTLd:差异为2.427天,显示瑞德西韦组患者平均提前恢复。
3.1.5 5. 结论与讨论
3.1.5.1 5.1 优势
- 直观解释:RMTLd以时间为单位,易于理解和临床应用。
- 模型鲁棒性:无需依赖比例风险假设,适用于复杂场景。
- 统计能力强:在非比例风险情况下性能优越。
3.1.5.2 5.2 应用建议
- RMTLd应作为cHR和sHR的补充,在竞争风险分析中联合报告。
- 在比例风险假设不成立时,可将RMTLd作为主要指标。
3.1.5.3 5.3 局限性
- 时间窗口的选择需结合具体领域知识。
- 本文实例分析旨在展示方法学,不直接提供临床结论。
3.1.6 6. 总结
这篇论文通过引入RMTLd,为竞争风险数据的分析提供了一种更为直观且稳健的方法,弥补了传统HR方法的不足,具有重要的临床与研究应用价值。
4 研究计划与目的
用(Tibshirani 等 2024)包的causal forest或者causal survival forest来估计基于RMST的survival treatment effect,
参考文献
Ding, Peng. 2023. 《A First Course in Causal Inference》. https://arxiv.org/abs/2305.18793.
Gelman, Andrew, 和 Aki Vehtari. 2021. 《What are the most important statistical ideas of the past 50 years?》 https://arxiv.org/abs/2012.00174.
Hernan, Miguel A, 和 James M Robins. 2025. Causal Inference: What If.
Hill, Austin Bradford. 1965. 《The environment and disease: association or causation?》 Journal of the Royal Society of Medicine 108 (1): 32–37. https://doi.org/10.1177/0141076814562718.
Hill, Sir Austin Bradford. 2022. 《The Environment and Disease: Association or Causation?》
Pearl, Judea. 1995. 《Causal Diagrams for Empirical Research》.
Shen, Haoning, Chengfeng Zhang, Yu Song, Zhiheng Huang, Yanjie Wang, Yawen Hou, 和 Zheng Chen. 2024. 《Assessing treatment effects with adjusted restricted mean time lost in observational competing risks data》. BMC Medical Research Methodology 24 (1): 186. https://doi.org/10.1186/s12874-024-02303-5.
Tennant, Peter W G, Eleanor J Murray, Kellyn F Arnold, Laurie Berrie, Matthew P Fox, Sarah C Gadd, Wendy J Harrison, 等. 2020. 《Use of directed acyclic graphs (DAGs) to identify confounders in applied health research: review and recommendations》. International Journal of Epidemiology 50 (2): 620–32. https://doi.org/10.1093/ije/dyaa213.
Tibshirani, Julie, Susan Athey, Erik Sverdrup, 和 Stefan Wager. 2024. 《grf: Generalized Random Forests》. https://CRAN.R-project.org/package=grf.
Wu, Hongji, Haoning Yuan, Zhen Yang, Yawen Hou, 和 Zheng Chen. 2022. 《Implementation of an Alternative Method for Assessing Competing Risks: Restricted Mean Time Lost》. American Journal of Epidemiology 191 (1): 163–72. https://doi.org/10.1093/aje/kwab235.
Wu, Hongji, Chengfeng Zhang, Yawen Hou, 和 Zheng Chen. 2023. 《Communicating and understanding statistical measures when quantifying the between-group difference in competing risks》. International Journal of Epidemiology 52 (6): 1975–83. https://doi.org/10.1093/ije/dyad127.
Yao, Liuyi, Zhixuan Chu, Sheng Li, Yaliang Li, Jing Gao, 和 Aidong Zhang. 2021. 《A Survey on Causal Inference》. ACM Trans. Knowl. Discov. Data 15 (5). https://doi.org/10.1145/3444944.
附录
hahaha